- algorithm-reading
- leetcode/lintcode题解/算法学习笔记
- 1. Part I - Basics
- 2. Data Structure
- 3. Basics Sorting
- 4. Basics Misc
- 5. Part II - Coding
- 6. String - 字符串
-
7.
Integer Array - 整型数组
- 7.1. Remove Element
- 7.2. Zero Sum Subarray
- 7.3. Subarray Sum K
- 7.4. Subarray Sum Closest
- 7.5. Product of Array Exclude Itself
- 7.6. Partition Array
- 7.7. First Missing Positive
- 7.8. 2 Sum
- 7.9. 3 Sum
- 7.10. 3 Sum Closest
- 7.11. Remove Duplicates from Sorted Array
- 7.12. Remove Duplicates from Sorted Array II
- 7.13. Merge Sorted Array
- 7.14. Merge Sorted Array II
- 7.15. Median
-
8.
Binary Search - 二分搜索
- 8.1. Binary Search
- 8.2. Search Insert Position
- 8.3. Search for a Range
- 8.4. First Bad Version
- 8.5. Search a 2D Matrix
- 8.6. Find Peak Element
- 8.7. Search in Rotated Sorted Array
- 8.8. Find Minimum in Rotated Sorted Array
- 8.9. Search a 2D Matrix II
- 8.10. Median of two Sorted Arrays
- 8.11. Sqrt x
- 8.12. Wood Cut
- 9. Math and Bit Manipulation - 数学技巧与位运算
-
10.
Linked List - 链表
- 10.1. Remove Duplicates from Sorted List
- 10.2. Remove Duplicates from Sorted List II
- 10.3. Remove Duplicates from Unsorted List
- 10.4. Partition List
- 10.5. Two Lists Sum
- 10.6. Two Lists Sum Advanced
- 10.7. Remove Nth Node From End of List
- 10.8. Linked List Cycle
- 10.9. Linked List Cycle II
- 10.10. Reverse Linked List
- 10.11. Reverse Linked List II
- 10.12. Merge Two Sorted Lists
- 10.13. Merge k Sorted Lists
- 10.14. Reorder List
- 10.15. Copy List with Random Pointer
- 10.16. Sort List
- 10.17. Insertion Sort List
- 10.18. Check if a singly linked list is palindrome
- 11. Reverse - 翻转法
- 12. Binary Tree - 二叉树
- 13. Binary Search Tree - 二叉搜索树
- 14. Exhaustive Search - 穷竭搜索
- 15. Dynamic Programming - 动态规划
- 16. Appendix I Interview and Resume
Binary Tree - 二叉树
二叉树是每个节点最多有两个子树的树结构,子树有左右之分,二叉树常被用于实现二叉查找树和二叉堆。
二叉树的第i层至多有 个结点;深度为k的二叉树至多有 个结点;对任何一棵二叉树T,如果其终端结点数为 , 度为2的结点数为 , 则 。
一棵深度为 , 且有 个节点称之为满二叉树;深度为 ,有 个节点的二叉树,当且仅当其每一个节点都与深度为 的满二叉树中,序号为 至 的节点对应时,称之为完全二叉树。完全二叉树中重在节点标号对应。
树的遍历
从二叉树的根节点出发,节点的遍历分为三个主要步骤:对当前节点进行操作(称为“访问”节点,或者根节点)、遍历左边子节点、遍历右边子节点。访问节点顺序的不同也就形成了不同的遍历方式。需要注意的是树的遍历通常使用递归的方法进行理解和实现,在访问元素时也需要使用递归的思想去理解。
按照访问根元素(当前元素)的前后顺序,遍历方式可划分为如下几种:
- 深度优先:先访问子节点,再访问父节点,最后访问第二个子节点。根据根节点相对于左右子节点的访问先后顺序又可细分为以下三种方式。
- 前序(pre-order):先根后左再右
- 中序(in-order):先左后根再右
- 后序(post-order):先左后右再根
- 广度优先:先访问根节点,沿着树的宽度遍历子节点,直到所有节点均被访问为止。
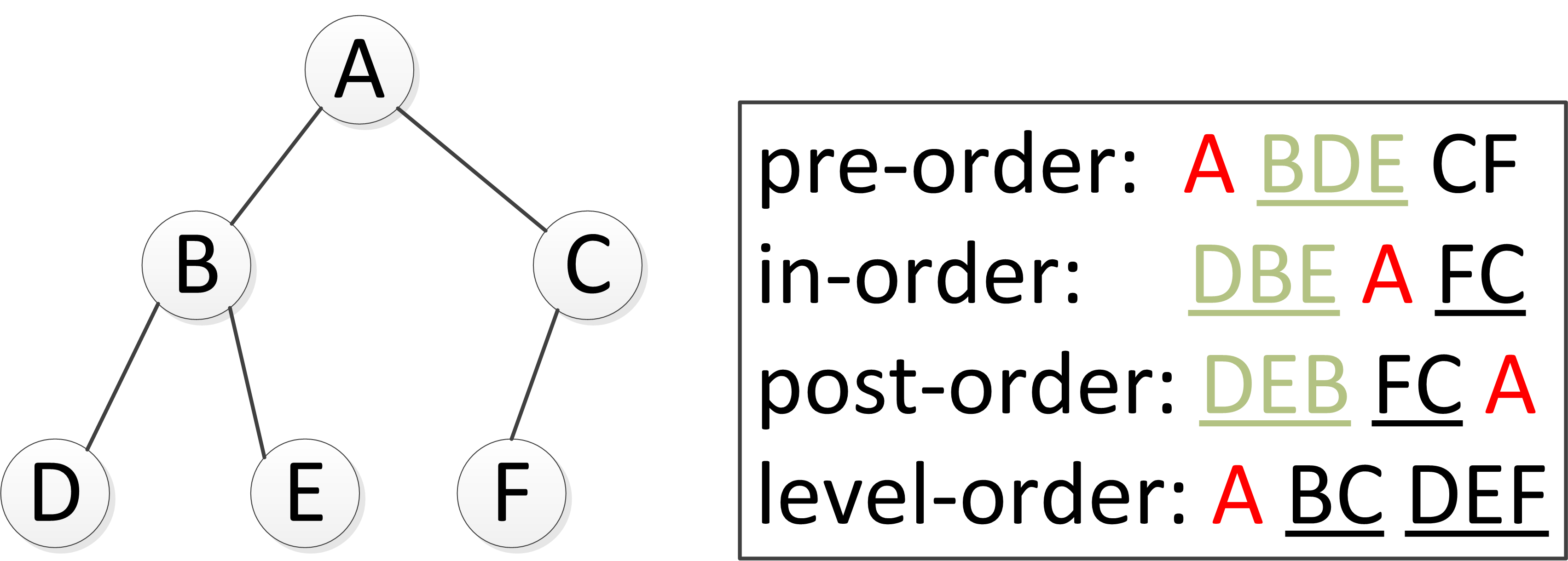
如下图所示,遍历顺序在右侧框中,红色A为根节点。使用递归和整体的思想去分析遍历顺序较为清晰。
二叉树的广度优先遍历和树的前序/中序/后序遍历不太一样,前/中/后序遍历使用递归,也就是栈的思想对二叉树进行遍历,广度优先一般使用队列的思想对二叉树进行遍历。
节点定义
这里的节点统一使用LeetCode的定义
struct TreeNode {
int val;
TreeNode *left;
TreeNode *right;
TreeNode(int x) : val(x), left(NULL), right(NULL) {}
};
相关算法——递归法遍历
pre-order travese
相关算法——分治法(Divide & Conquer)
在计算机科学中,分治法是一种很重要的算法。分治法即“分而治之”,把一个复杂的问题分成两个或更多的相同或相似的子问题,再把子问题分成更小的子问题……直到最后子问题可以简单的直接求解,原问题的解即子问题的解的合并。这个思想是很多高效算法的基础,如排序算法(快速排序,归并排序)等。
分治法思想
分治法所能解决的问题一般具有以下几个特征:
- 问题的规模缩小到一定的程度就可以容易地解决。
- 问题可以分解为若干个规模较小的相同问题,即该问题具有最优子结构性质。
- 利用该问题分解出的子问题的解可以合并为该问题的解。
- 该问题所分解出的各个子问题是相互独立的,即子问题之间不包含公共的子问题。
分治法的三个步骤是:
- 分解(Divide):将原问题分解为若干子问题,这些子问题都是原问题规模较小的实例。
- 解决(Conquer):递归地求解各子问题。如果子问题规模足够小,则直接求解。
- 合并(Combine):将所有子问题的解合并为原问题的解。
分治法的经典题目:
- 二分搜索
- 大整数乘法
- Strassen矩阵乘法
- 棋盘覆盖
- 归并排序
- 快速排序
- 循环赛日程表
- 汉诺塔
树类题的复杂度分析
对树相关的题进行复杂度分析时可统计对每个节点被访问的次数,进而求得总的时间复杂度。